For this week’s Sunday Reading Notes, I am switching topics towards bayesian computations and machine learning. This week’s paper is ‘Practice Bayesian Optimization of Machine Learning Algorithms‘ by Jasper Snoek, Hugo Larochelle and Ryan Adams, and it appeared on NIPS 2012.
On the high level, Bayesian optimization is about fitting Gaussian Process(GP) regression on data currently observed about some black-box function 

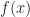
When I first read the paper, I was asking myself: why do we need Bayesian optimization? How does it compare to other optimization methods we learned, for example Gradient Descent? Wouldn’t a grid search on the domain give a much better optimization result? I think to answer these questions, we have to keep remind ourselves that we are optimizing some black-box function, whose gradient is unknown. And what’s more, this function is very expensive to evaluate and we can not afford to perform a grid-search on it. As an example, think about tuning parameters for a neural network. Admittedly Bayesian optimization can be expensive as well, therefore we would choose to use Bayesian optimization over grid-search when all the integration and maximization involved in choosing 

We start with putting on GP prior on 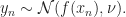
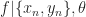


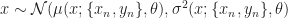
If the current best value is 

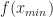

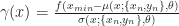

The most interesting section in this paper is Section 3: practical considerations, where the authors goes through
- choice of covariance function;
- treatment of hyper-parameter;
- modeling cost;
- parallelization.
The first two issues also appear in the GPML book. Basically in this paper the authors recommend the Matern 5/2 kernel because it only assumes twice-twice-differentiabiltiy. The squared exponential kernel is the default choice for GP regression, but its smoothness assumption is unrealistic more most machine learning algorithms.
For choosing hyper-parameters, we can choose hyper-parameters that maximize the marginal likelihood function. For a full Bayesian treatment, we have to marginalize over the hyper-parameters and work with the integrated acquisition function 
As both opti- mization and Markov chain Monte Carlo are computationally dominated by the cubic cost of solving an N -dimensional linear system (and our function evaluations are assumed to be much more expen- sive anyway), the fully-Bayesian treatment is sensible and our empirical evaluations bear this out.
I have played with this algorithm myself on some simple functions like Brainin-Hoo function. I’d like to try how this function works on more complicated functions, like online LDA, Latent Structured SVM, and convolutional neural nets.
Lastly, to get some sense of how expensive the computations are, I want to show Figure 4 in the paper.

If we look at (4b) on the axis, the unit of time is days! In terms of Function evaluations, the Bayesian optimization algorithm dominates a random grid search from a very early stage. In (4a) GP EI MCMC, which uses the least parallelizations is the most efficient in terms of function evaluations, but when we look at (4b) it could take longer time (measured by days!).

One thought on “Sunday Reading Notes – Bayesian Optimization”