I am very interested in exploration-exploitation trade-off. In a previous Sunday Reading Notes post, I discussed bayesian optimization for learning optimal hyper-parameters for machine learning algorithms, as an example for this trade-off. Today I study another exploration-exploitation algorithm for learning the best assortment: A Near-Optimal Exploration-Exploitation Approach for Assortment Selection by Agrawal et al. It has applications in online advertisement display and recommendation systems for e-commerce.
If we take the recommendation system for e-commerce websites as an example. Suppose this website has 

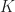

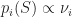
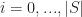


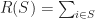

In the optimization, we want to minimize the cumulative regret until time 
![reg(T) = \sum_{t=1}^T R(S^\star) - \mathbb{E}\left[R(S_t) \right]](https://s0.wp.com/latex.php?latex=reg%28T%29+%3D+%5Csum_%7Bt%3D1%7D%5ET+R%28S%5E%5Cstar%29+-+%5Cmathbb%7BE%7D%5Cleft%5BR%28S_t%29+%5Cright%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

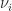
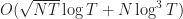
Section 4 gives the proof of the main theorem and it is in my opinion very well-written. Proof outline is given in Section 4.1 and the authors marked the 3 steps of the proof, which are detailed later in Sections 4.2 – 4.4.
The exploration-exportation algorithm for bandit-MNL algorithm in Algorithm I iterations between learning the current best possible recommendation with using static assortment optimization methods. After recommending the calculated assortment to a customer, they observe purchasing decisions of customers until a no-purchase happens. Using information form user purchases, we can learn upper confidence bounds of model parameters $later \nu_{i}.$ The UCB estimates are used to find the assortment for the next iteration. This process of going back between offering assortments and observing purchase decisions continuous until
In my opinion, this paper lies on the theoretical end of the spectrum and their is no simulation results or real-data examples accompanying the theoretical results. It would be nice to see some visualization of the cumulative regret with this algorithm and how it compare to the theoretical lower bound presented in Section 5.
I have two idea of how this problems can be extended to accommodate for complex applied problems. For examples, 1) item prices are assumed to be known for now. It would be interesting extension for this paper to see if we can treat
References:
- Agrawal, Shipra, et al. “A near-optimal exploration-exploitation approach for assortment selection.” Proceedings of the 2016 ACM Conference on Economics and Computation. ACM, 2016.
