The Sunday Reading Notes (SRN) series is back! This Sunday’s topic is Bayesian A/B tests. Last month, I wrote a post on Bayesian continuous monitoring, commenting on the DSAA’16 paper Continuous Monitoring of A/B Tests without Pain by Deng et al.
In that paper, the main take away is that peeking is not a problem in Bayesian A/B tests if we use genuine priors and prior odds, and Bayesian A/B tests controls False Discovery Rate (FDR). In this paper, the authors mention that we can learn an objective prior from empirical data, instead of using non-infomration priors in Bayesian A/B tests.
Practical prior specification for Bayesian statistics is a big topic. Yesterday I met a machine learning engineer at a BBQ and told him that I have been thinking about objective prior learning and earning stopping for Bayesian A/B tests. His reaction was: don’t you know conjugate priors? don’t you know that priors will be overwhelmed by data very soon? My response was: yes you can use conjugate priors because it’s convenient. But I am not sure if we still want to assume we are in the asymptotic regime when we want to do an early stopping in A/B tests. While I convinced by him and myself with this argument, I am not sure whether this is the only reason prior specification matters in A/B tests. I’d be super happy if there can be some discussions in the comments!
Going back to Deng’s paper, to use priors learned from past experiments for a new test, the only assumption we need to make is that we assume the prior behinds these experiments are the same. This would happen because the variants are designed by the same group of engineers and the treatment effort would have the same distribution. We assume that observations in control come i.i.d. from some distribution with mean 
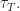
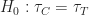

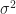
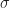

We need to learn the prior odds 
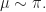

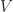
Once the model is set-up, the procedure is straight-forward. What I find most interesting in this paper is Section 3.4 where the author discuss problems of the Beta-Bernoulli model, which is what people usually use for conversion rates or click-through-rates experiments. The first practical problem comes from a miss match between the experiment randomizing on the user-level while the model assumes page-views being iid. The second problem, which I honestly do not quite understand, is that the conjugate Beta prior cannot be a genuine prior. I wish the author had elaborated more on this point because conversion rate is tested so often in online experiments.
When the author concludes the paper, he talks about what we should do if there are not thousands experiments from which we can learn an objective prior. He talks about the trade-off between the sample size of using all the experiments and the precision from using only relevant experiments. To this end, he suggests setting up a hierarchical model.
I really like this paper and I have read it several times. Every time I read it, I learn a little more about Bayesian A/B tests. I like how it is a good blend of technical derivations, practical considerations and philosophical discussions.While reading the paper, I kind of feel that the author needs more space than what the page limit had given him. Because there are so many places where I hope he had elaborates on or given more details about. The DSAA’16 paper is a follow up on optional stopping for Bayesian A/B tests. I am personally very intrigued by the Beta-Bernoulli discussions and I also want to learn more about what the author has to say about multiple-testing!
