While browsing the accepted papers list of ICML 2018, I discovered this paper ‘Racing Thompson: an Efficient Algorithm for Thompson Sampling with Non-conjugate Priors‘ by Zhou, Zhu, and Zhuo. Thompson sampling is a popular algorithm for exploration-exploitation tradeoff problems and is also known as Bayesian bandits. I decided to write my Sunday Reading Notes post on this paper because have been interested in the exploration-exploitation tradeoff for a while and explored this topic through Bayesian optimization and my WSDM’19 paper on sequential A/B testing.
Suppose we want to identify the best arm among 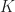
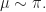

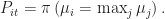

![\pi\left( \mu_i = \max_j \mu_j \right) = \mathbb{E}_{\mu\sim \pi(\cdot|X(1:t))}\left[\mathbb{I}[\mu_k = \max_j {\mu_j}] \right] = \mathbb{E}_{\mu\sim B_t}\left[\mathbb{I}[\mu_k = \max_j {\mu_j}] \frac{\pi(\mu|X(1:t)}{B_t(\mu}\right].](https://s0.wp.com/latex.php?latex=%5Cpi%5Cleft%28+%5Cmu_i+%3D+%5Cmax_j+%5Cmu_j+%5Cright%29+%3D%C2%A0+%5Cmathbb%7BE%7D_%7B%5Cmu%5Csim+%5Cpi%28%5Ccdot%7CX%281%3At%29%29%7D%5Cleft%5B%5Cmathbb%7BI%7D%5B%5Cmu_k+%3D+%5Cmax_j+%7B%5Cmu_j%7D%5D+%5Cright%5D+%3D+%5Cmathbb%7BE%7D_%7B%5Cmu%5Csim+B_t%7D%5Cleft%5B%5Cmathbb%7BI%7D%5B%5Cmu_k+%3D+%5Cmax_j+%7B%5Cmu_j%7D%5D+%5Cfrac%7B%5Cpi%28%5Cmu%7CX%281%3At%29%7D%7BB_t%28%5Cmu%7D%5Cright%5D.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The benefits of this IS step comes from flexibility to choose $B_t$ at each time step and also the authors leveraged the stopping rule of racing algorithms to deterime the number of IS samples needed to approximate the expectation.
The resulting algorithm, which combines benefits from Importance Sampling, Gumble-Max trick, and the racing algorithm, is proved to be 

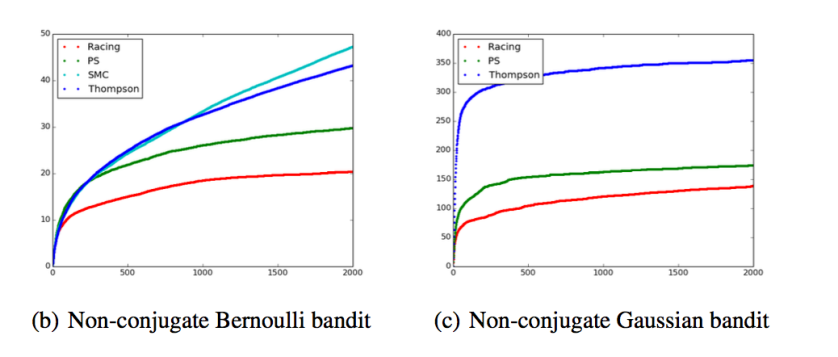
What I find very interesting from the regret analysis section is the fact that the racing TS in this paper can provide much lower regret compared to Thompson sampling and prior-swapping (PS) even though it uses much few particles than SMC and PS. It is not intuitive to me why this should happen. But upon a little further investigation, I found that the priors used for TS and PS & Racing are different in both plots. For ease of implementation, the authors have chosen a conjugate prior for TS. This leaves me wondering what the results would be if we were to use MCMC or SMC with more particles as the baseline for the regret analysis.
References:
- Zhou, Y., Zhu, J. & Zhuo, J.. (2018). Racing Thompson: an Efficient Algorithm for Thompson Sampling with Non-conjugate Priors. Proceedings of the 35th International Conference on Machine Learning, in PMLR 80:6000-6008
