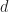n this week’s Sunday Reading Notes, I discuss the paper Distilling Importance Sampling by Dennis Prangle. It aims to find the normalising flow $latex q$ that minimizes the distance to the target distribution $latex p$.
In this week’s Sunday Reading Notes, I discuss the paper Distilling Importance Sampling by Dennis Prangle. It aims to find the normalising flow that minimizes the distance to the target distribution . DIS uses the inclusive Kulbleck-Leiber divergence (KL divergence from the target distribution to the approximating distribution ), in order to avoid over-concentration. The process of distilling refers to utilizing tempering distributions that converges to . In each step, DIS using stochastic gradient descent to minimize KL from to where the gradients are estimated with self-normalized importance sampling.
Recently I came across many papers involving both Monte Carlo methods and neural networks. I learned many new concepts, among them, was normalising flow. A normalising flow is a bijective transformation from simple distributions such as normal or uniform. This paper considers non-volume preserving (NVP) normalising flow, particularly the coupling layer. It transforms input vector into output vector by fixing coordinates and shifting and scaling the remaining coordinates by neural network outputs. The resulting family of densities can be sampled rapidly and their gradients are computable.
One question I have while reading this paper is about convergence guarantees. What does the distribution converge to? Numerical experiments suggest that DIS output is very close to the targeting distribution by comparing it to MCMC output. But as Prangle acknowledges, DIS output has less accurate tails than those of MCMC. Intuitively speaking DIS output should converge to the argmin of inclusive KL from target distribution to normalising flows. But does the distilling procedure guarantee convergence, despite the gradient estimates and tempering steps? I also keep thinking about what would be the SMC counterpart of DIS.
Figure 3 from Prangle, 2019. Comparing MCMC output and DIS output for the M/G/1 queueing example.